Eleva
Accessibility infrastructure for human–AI work.
Orchestration layers of working memory for LLM systems.
Accessibility infrastructure for human–AI work.
Orchestration layers of working memory for LLM systems.
A mission-driven orchestration layer for academic and school work assisted by LLMs, with a focus on cognitive accessibility.
Interfaces that respect attention, memory, and neurodiversity. Bringing measurable, objective outcomes in accessibility, and a reduction of energy demands by reducing computational costs through efficient systems.
Grounded philosophy translated into usable systems. Driven by need: designing "working memory" layers for AI agents powered by LLMs. Leveraging interdisciplinary systems design.
Helping our clients optimize costs and seize incentives related to the development and adoption of technologies providing cognitive accessibility.
This research explores a UI–backend orchestration layer that externalizes “working memory” for LLM-assisted work. The system mediates context, intent, and state across interactions, allowing users to reason, revisit, and intervene in how memory is constructed, persisted, and retrieved—without collapsing cognition into a single prompt or session.
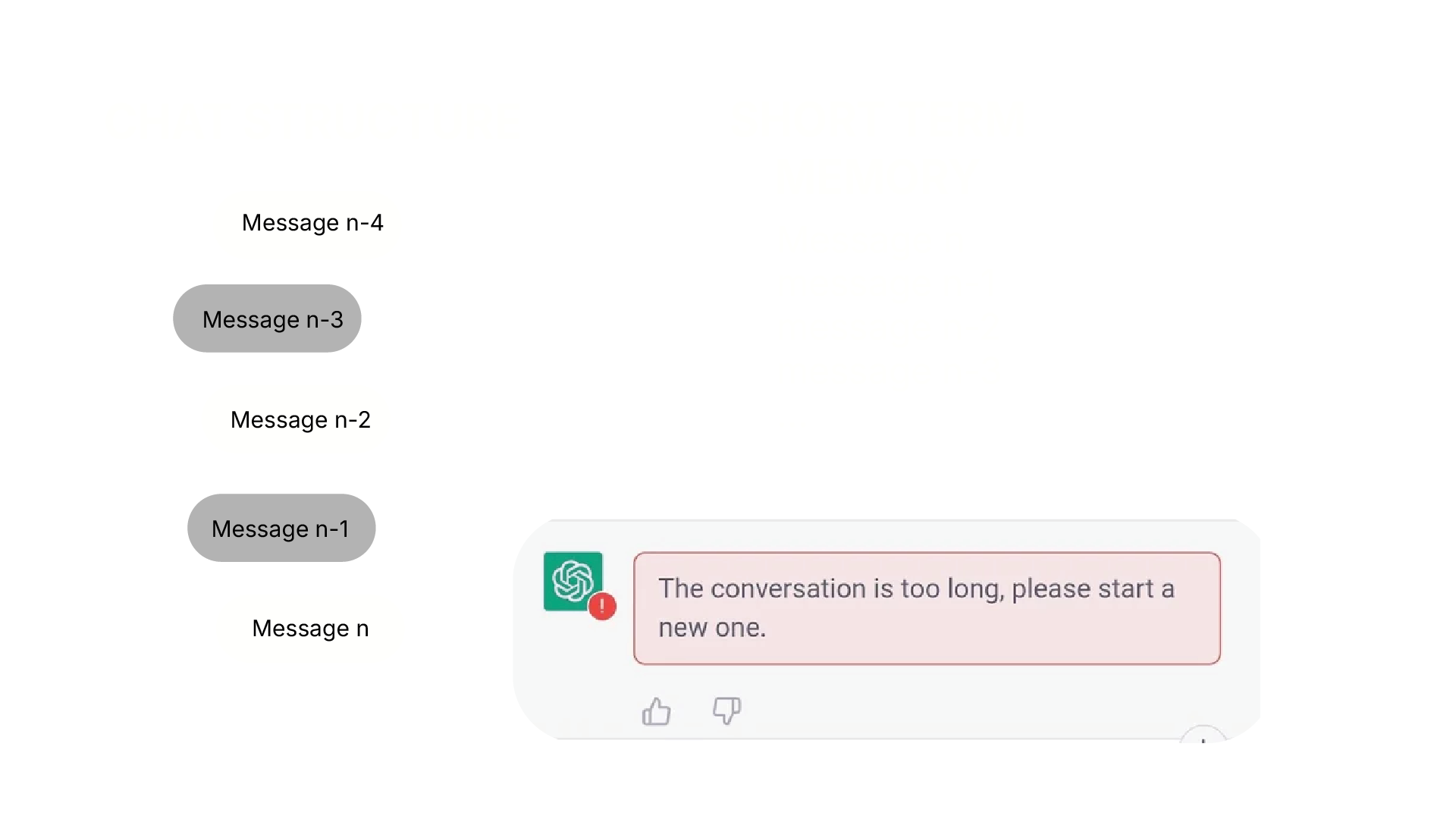
A chat interface is conversationally intuitive but computationally inefficient.
A chat-based interface can become computationally inefficient because standard transformer models scale quadratically with context length. In an unoptimized chat structure, the “short-term memory” includes all the previous messages in the next prompt.
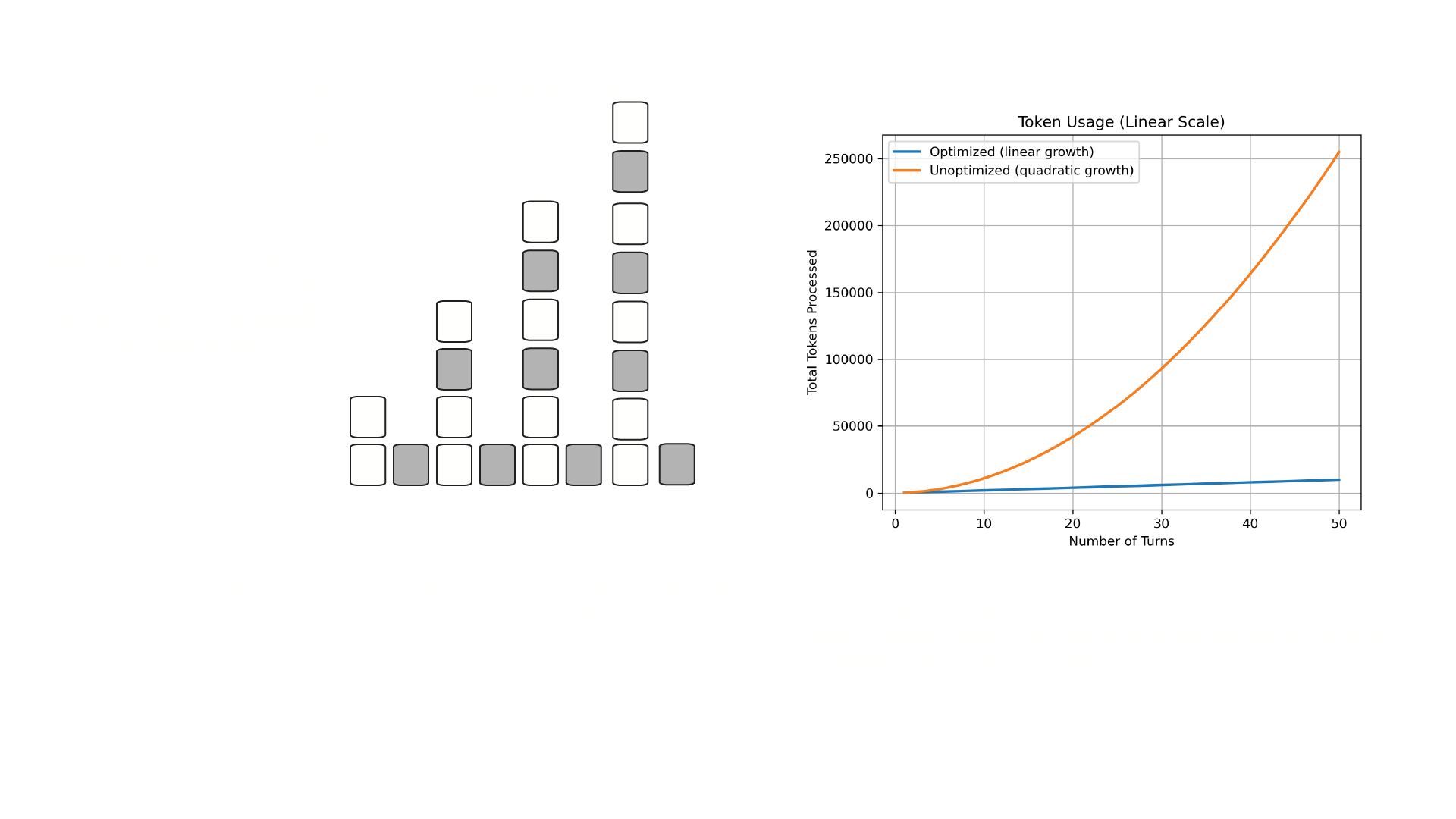
If a conversation contains N tokens, generating each new token requires comparing it against all previous tokens, resulting in O(N²) work. As chats grow longer, this dramatically increases computation, memory use, and response time —ultimately leading to higher energy consumption and a larger environmental footprint. This is why strategies like context preservation, chunking, and minimizing unnecessary tokens are not just good UX practices; they are directly connected to sustainability, accessibility, and more equitable AI systems.
On top of the problem of the quadratic growth of the token usage in long conversations, chat-based UI with LLMs also induce or guide users to a misuse of the tool. The most evident could be that people can conceive a chat as a person to talk to about everything, and the lack of guidelines can allow users to try to use LLMs in ways they are not intended to (for example, using them as therapists, or for identity theft). But even in users who understand the limitations of LLMs, a chat-based user interface replicates common challenges associated to conversations. For example, having to be verbally fluent, or having the attention span to filter out what is important from what is not, common challenges for neurodivergent people. Also, overreliance on these tools can make us more dependent on them. “Give me the full code” is a perfect example of how we can process tokens unnecessarily, just for the sake of clarity, to prevent confusion, or for laziness, leading to computational and environmental waste.
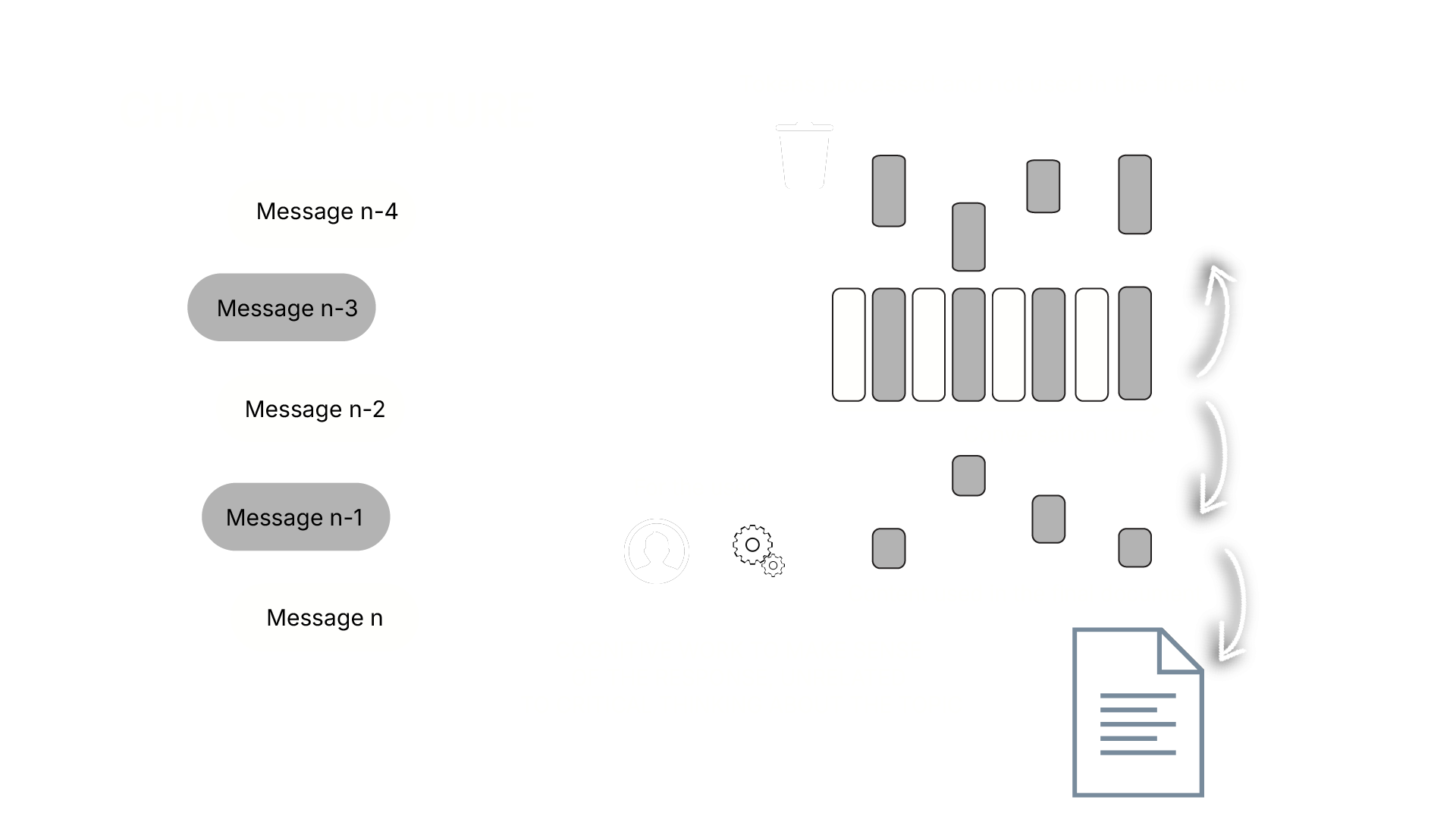
A unified layer for LLM-assisted knowledge work
My project proposal is a web application with to assist and guide users generate code. It works as an accessibility tool, meeting WCAG (Web Content Accessibility Guidelines) guidelines of chunking, and applying data visualization to substitute for short attention span limitations, helpful for everyone, but especially helpful and inclusive for neurodivergent users. Our backend will process user prompts and build strategic, minimalistic data structures storing the relevant “context”, which will be the most recent code, to use as the “short-term memory” of the LLM agent, eliminating the need for chat-based structures. Our algorithm to restructure the short term memory, or attention, of our web application can be a solution to reduce the quadratic growth of the token usage
User flow
The system leverages chat interfaces, structured memory objects, and visualization of memory traces to create a reflective and iterative workflow. Users can inspect, revise, and replay contextual states seamlessly.
ONGOING RESEARCH